Parallel Distributed Processing DRAFT
Note
This chapter authored by Todd M. Gureckis. See the license information for this book. The draft chapter means it should not be considered complete or accurate!!
Introduction
In 1986, David Rumelhart, James McClelland, and the PDP Research Group published Parallel Distributed Processing, arguing that cognition emerges from networks of simple, neuron-like units working in parallel.
The PDP approach, also called connectionism, offered an alternative to modeling the mind as a serial symbol-processing computer. Instead of explicit rules manipulating discrete symbols, PDP models store knowledge in connection weights, and intelligent behavior emerges from parallel interactions of simple units.
What Kind of Computer is the Mind?
When we look closely at the brain, it looks nothing like a traditional computer, for several reasons:
- Massive parallelism: Around 86 billion neurons, each connected to thousands of others, all processing simultaneously. While modern computers enable multiple threads of execution, they are still fundamentally serial.
- Distributed representation: Knowledge is spread across patterns of activity, not stored in single locations.
- Slow components, fast behavior: Neurons fire at roughly 100 Hz (100 times per second or once every 10 milliseconds), yet in that same time we can do fairly complex tasks like recognizing a face. Parallelism and the storage of information in distributed patterns is essential.
The PDP approach to cognitive modeling asks "What computation emerges from brain-like hardware?" rather than "What algorithm does the mind run?"
INFO
PDP models often explore connectionist computation, not biological accuracy. The goal is discovering what properties emerge from this style of modeling (distributed representation, emergent behavior) rather than faithfully replicating neural circuitry. It uses simplified simulations to help give us better intuitions for how these systems might work.
Key Principles of PDP
As a modeling approach, PDP adopts several key principles which are unique or different from other approaches to cognitive modeling.
Neurally-Inspired Computation
The models are composed of simple processing units which are loosely inspired by neurons. Each processing unit:
- Receives weighted inputs from other units
- Computes a weighted sum plus bias
- Applies an activation function
- Sends output to other units
The weights share similarities with synapses which connect neurons in the brain. Synapses change their effectiveness based on the activity of the pre-synaptic neuron and longer-term changes in synaptic strength can be induced by learning. In PDP system the network weights encode knowledge. Learning adjusts weights.
Intelligence as an Emergent Phenomenon
Complex behavior emerges from interactions of simple components. No single unit "knows" the answer. In PDP systems, we don't program explicit rules; instead, we create conditions from which intelligent behavior emerges.
Simulation is Central
Emergent behavior is hard to predict analytically. We must build models, run them, and observe what happens. This positions cognitive science as a computational science -- one that relies heavily on computational techniques.
Cognition as Soft Constraint Satisfaction
Cognition often means simultaneously satisfying many soft constraints: preferences that push and pull, none absolutely rigid.
Parallel constraint satisfaction (i.e., solutions to these problems) differ sharply from rule-following or discrete search. In connectionist networks, constraints are weights, and the network often settles into states that best satisfy them without obeying hard and fast rules. This framework applies to perception, language, memory, and decision-making. The "answer" emerges from collective settling, not explicit rules.Example: Reaching for the salt
Consider reaching for the salt at a crowded dinner table. You need to balance multiple constraints: move toward the salt, avoid wine glasses, don't drag your sleeve through butter, maintain balance, avoid your neighbor's elbow. No constraint is inviolable (you might brush a glass), but each influences the trajectory. The solution satisfies all constraints as well as possible.
Emergence: Complex Behavior from Simple Rules
Emergence is central to PDP. Systems exhibit behaviors that can't be predicted from their component rules alone and must be revealed through simulation.Conway's Game of Life
Conway's Game of Life (1970) demonstrates an fun example of emergence. In the "game" there is a set of cells on a two dimensional grid.Cells on a grid are alive or dead, and their state (alive or dead) evolves over time according to four rules:
- Underpopulation: Live cell with < 2 neighbors dies
- Survival: Live cell with 2-3 neighbors survives
- Overpopulation: Live cell with > 3 neighbors dies
- Reproduction: Dead cell with exactly 3 neighbors becomes alive
You can play with a simulation of the game:
You can play with putting in random initial conditions with your mouse and observing the emergent behavior. But on the side are specfic initial patterns that you are encouraged to try. These patterns were "discovered" by Conway and others who were playing with the game.
What is striking is that you detect some type of cohesive structure to some of these initial patterns (moving shapes, oscillating patterns, etc.). But these are not mentioned in the rules themselves. You cannot deduce these behaviors by reading the rules; you must run the system and observe.
Exrapolating this to cognition and the brain, we can imagine that memories, concepts, and thoughts may emerge from interactions of simple neuron-like units. No single unit "knows" anything. Intelligence emerges from collective dynamics.
The Artificial Neuron
The basic building block of PDP models is the artificial neuron or "unit," a simplified abstraction of biological neurons that captures key computational properties without biological realism.
The block building block of PDP models is the artificial neuron or "unit," a simplified abstraction of biological neurons that captures key computational properties without biological realism.
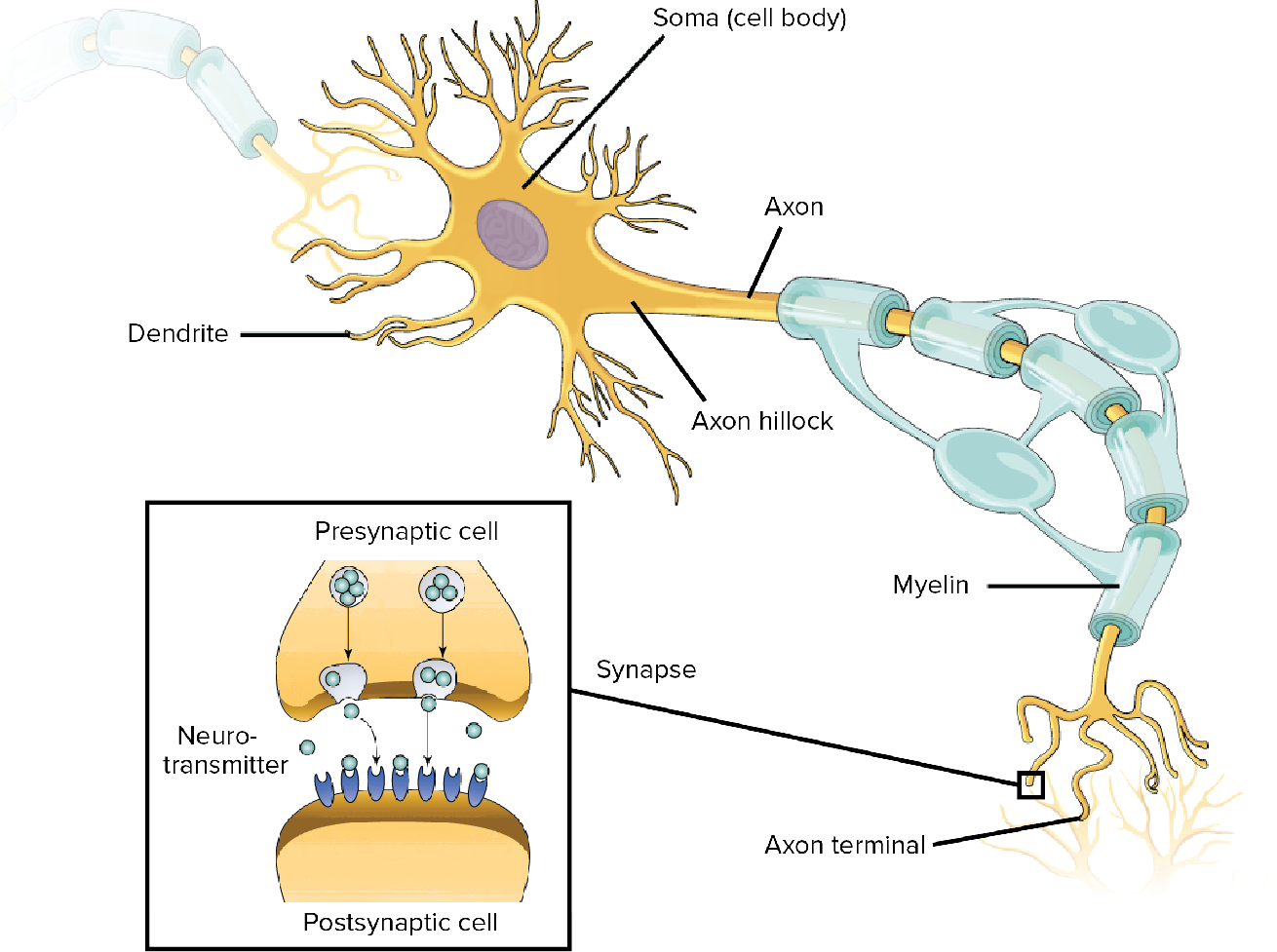
Biological neurons receive signals through dendrites, integrate them in the soma, and transmit output via axons. Image from OpenStax Biology.
The artificial neuron abstracts this into:

The artificial neuron: inputs are weighted, summed, and passed through an activation function.
- Inputs from other units or the environment2. Weights determining connection strength (analogous to synaptic strength)
- Weighted sum of inputs, passed through an activation function
TIP
Key point for PDP In PDP models, knowledge is stored in the weights. Learning means adjusting connection strengths based on experience. The "intelligence" doesn't reside in any single unit. It emerges from the pattern of connectivity.
The XOR Problem and Hidden Layers
A single perceptron can only learn functions where classes are separable by a straight line. The famous example it cannot learn is XOR (exclusive or).
The "AI Winter"
This limitation was highlighted by Minsky and Papert in 1969, contributing to reduced interest in neural networks for over a decade.
For the mathematical details, including the perceptron, activation functions, computing logical functions like OR and AND, and the famous XOR limitation, see the Math for Neural Networks chapter. The key idea in PDP is that single units are limited, but networks of units can learn complex functions.
The Perceptron is one of the simplest neuron models, but PDP explored many others, including neurons which have more continuous activation outputs and which vary in time.
Example PDP Model: The Interactive Activation Model
The Interactive Activation and Competition (IAC) model (McClelland, 1981) demonstrates how PDP principles explain memory retrieval. This is a classic model that has been used to explain a variety of cognitive phenomena, including memory retrieval, decision making, and language processing.
The Problem: Content-Addressable Memory
A friend says: "I met someone you know. Short black hair, glasses, goes to your school..."
You can often retrieve the person's name from just a few properties. This ability is called content-addressable memory: retrieving information from partial content, not an explicit address.
This is quite different from the way computers typically store information. For example, a database can store this information, but retrieval is sequential, brittle to errors, and can't generalize. Databases (or looking up files on your computer) usually rely on an explicit address or key to find a document.
How could the brain implement content-addressable memory?
The IAC Architecture
The IAC model is composed of a network of interconnected units. Each unit has a continuous activation value that can be updated over time. The units are organized into two layers or neuron types (pink and green in the figure below):
- Property units: Each property (hair color, glasses, etc.) is represented by a single unit, organized into pools.
- Hidden units: Each hidden unit is a single unit that is not directly visible to the outside world. Each person in memory is represented by a single unit.
The units are connected by excitatory connections and inhibitory connections . Excitatory connections are positive weights that increase the activation of the receiving unit. Inhibitory connections are negative weights that decrease the activation of the receiving unit.

The Interactive Activation and Competition model. Instance units (people) connect to property units through excitatory connections. Properties within a pool inhibit each other.
How the IAC Model Works
Units in the IAC model have continuous activation values that update over time. Positive input pushes activation toward maximum; negative input pushes toward minimum. This creates "rich get richer" dynamics: units with slightly more activation tend to dominate.
The IAC Update Rule (Mathematical Details) determines the output at time
here
The details of this aren't especially important right now, but it's useful to understand how the dynamics continually evolve do to the influence of other connected units ($\textbf{net}) over time.
Exploring the Dynamics: A Competitive Pool
You can build intuition by isolating a single pool of neurons with lateral inhibition — the same mechanism that creates competition within each pool of the full IAC model. In the demo below, all five neurons inhibit each other. All neurons start at their resting activation (zero), so nothing happens until you provide input. Click a neuron to apply external input (shown by a green border) — this gives that neuron a sustained positive drive each cycle. Each click cycles through increasing input levels (0.25, 0.50, 0.75, 1.0, then back to off), so you can give different neurons different amounts of input. This external drive is analogous to excitatory input arriving from another pool in the full network.
Key experiments
- Mutual excitation (positive weight): Both neurons rise together; the higher one stays ahead
- Competition (negative weight): One suppresses the other; small differences get amplified
- External input: Click a neuron to give it input. This breaks ties and determines the winner.
These are exactly the dynamics at work in the full IAC model. Within each pool (names, features, hidden units), lateral inhibition creates competition. Excitatory connections between pools provide the external drive that determines which units win.
Try the Full IAC Model for the West Side Story
Explore with the Jets and Sharks (the names of the gangs in West Side Story) demo:
Things to try
- Retrieval by name: Click an instance unit (like "Art"), then "Run" to see activation spread to their properties
- Content-addressable retrieval: Activate properties (like "Sharks" + "20s") to retrieve matching people
- Graceful degradation: Activate properties that don't perfectly match. The network finds the closest match.
- Spontaneous generalization: Activate just "Jets" to see typical Jets properties emerge
For more details, see the IAC Demo page.
Emergent Properties
The IAC model exhibits remarkable properties that weren't explicitly programmed:
Content addressability: Retrieve people from partial property information through parallel constraint satisfaction
Graceful degradation: Unlike databases that fail with incorrect queries, the network retrieves the closest match. This is a hallmark of biological cognition.
Spontaneous generalization: Query "What are Jets like?" by activating the Jets unit. Properties shared by many members receive more activation. The network computes prototypes without explicitly storing them.
Limitations
- Hand-coded knowledge: Connections are set by hand, not learned. Later models using backpropagation learn weights from data.
- Limited capacity: Doesn't scale to large knowledge bases
- Simplified representations: Real semantic knowledge has richer structure
Despite these limitations, the IAC established key principles: knowledge in connection weights, behavior emerging from parallel constraint satisfaction, and cognitive phenomena arising naturally from architecture.
Example 2: Hopfield Networks and Boltzmann Machines
The IAC model shows how networks settle into states that satisfy constraints. Energy-based models provide a deeper framework for this computation, revealing connections between neural networks, physics, and memory.
The Energy Landscape Metaphor
Imagine a ball rolling on a hilly landscape. It settles into a valley without needing instructions; gravity and terrain determine its path.
Energy-based neural networks work similarly. An energy function assigns a number to each network state, and dynamics cause the network to "roll downhill" toward low-energy states. These low-energy states become the network's memories or solutions.
Notice that the ball doesn't always find the deepest valley (the global minimum). It finds the nearest one. This is both a feature and a limitation: efficient but not optimal. Techniques like simulated annealing (adding randomness) help escape poor local minima.
Hopfield Networks
In 1982, physicist John Hopfield made this energy framework explicit. A Hopfield network has units that are on (+1) or off (−1) with symmetric connections.
Details
Hopfield Network Energy (Mathematical Details)
where
When units update based on their inputs, energy never increases. The network always moves toward local minima.
We store memories by shaping the energy landscape, adjusting weights so desired patterns become valleys. Present a partial or noisy pattern, and the network settles into the complete memory. Memories act as attractors: nearby states are pulled toward them.
Boltzmann Machines
Boltzmann machines (Hinton & Sejnowski, 1985) add **randomness**. Units make probabilistic choices, with lower-energy states more likely:At high temperature, the network explores widely; at low temperature, it settles deterministically. This technique is called simulated annealing.
Randomness helps in two ways: escaping local minima and enabling learning (by comparing network statistics when shown data versus running freely).
Connections to Cognition
Energy-based models offer useful cognitive metaphors:
- Memory retrieval as energy minimization: settle into the nearest stored memory
- Perception as finding the low-energy interpretation of sensory input
- Decision making as exploring an energy landscape, with randomness helping avoid suboptimal choices
- Learning as shaping the landscape to create new attractors
INFO
Nobel Prize Recognition The 2024 Nobel Prize in Physics was awarded to John Hopfield and Geoffrey Hinton for this foundational work, recognizing how statistical physics transformed our understanding of learning in artificial neural networks.
From Energy Models to Modern Deep Learning
Boltzmann machines are rarely used directly today because they are computationally expensive. But their ideas persist: Restricted Boltzmann Machines enabled early deep learning, energy-based learning remains an active research area, and diffusion models powering modern image generation have deep connections to energy-based thinking.
Example 3: Complementary Learning Systems in the Brain
If the brain is a connectionist network, why does it have distinct memory systems?
The Problem of Catastrophic Interference
Connectionist networks that learn gradually excel at extracting statistical regularities. This is exactly what we want for semantic memory (general world knowledge).
But there's a problem. Training on new information can overwrite old learning, a phenomenon called catastrophic interference. Train a network on cats, then extensively on dogs, and it may forget cats entirely.
Humans don't forget cats when learning about dogs. How does the brain solve this?
Two Systems, Two Learning Rates
Complementary Learning Systems (CLS) theory (McClelland, McNaughton, & O'Reilly, 1995) proposes that brain architecture reflects a solution to catastrophic interference.The neocortex learns slowly, extracting statistical structure through distributed representations. It stores semantic knowledge (birds fly, dogs bark). It can't quickly store specific episodes without interference.
The hippocampus learns rapidly, encoding specific episodes with sparse, pattern-separated representations that minimize overlap. It stores episodic memories (what you had for breakfast).
Memory Consolidation
Knowledge transfers from hippocampus to neocortex through
memory consolidation, particularly during sleep. The hippocampus "replays" stored episodes to the neocortex, re-training it on past experiences _interleaved_ with new ones.Interleaved training is key. Networks trained on cats and dogs mixed together don't suffer catastrophic interference. This explains why sleep matters for memory, and why hippocampal damage causes
anterograde amnesia while leaving old knowledge intact.PDP and Brain Architecture
CLS exemplifies PDP thinking. It asks: what computational constraints does connectionist learning impose, and how might brain architecture reflect solutions? The hippocampus-neocortex division may be a necessary consequence of building learning systems from neuron-like components.
Criticisms of PDP
The PDP approach sparked vigorous debate. Critics raised fundamental objections that remain relevant today.
The Structure Problem
Fodor and Pylyshyn (1988) argued that human thought is
systematic:cognitive abilities come in clusters. If you can think "John loves Mary," you can think "Mary loves John." Classical symbolic systems get this for free. The same rules that represent one thought automatically enable related thoughts. But a connectionist network trained on "John loves Mary" might not generalize to "Mary loves John."
A related challenge is
variable binding. How does a network represent that _someone_ loves _someone else_ without specifying who? If "John" and "Mary" are activation patterns, how do you represent who is the lover versus beloved? Standard connectionist architectures lack obvious structure for this.Learning Without Backpropagation
While PDP was inspired by the brain, backpropagation is biologically implausible. It requires error signals propagating backward, symmetric weights, and global error information. None of these match real neural circuits. How the brain achieves effective credit assignment remains an open question.
The Black Box Problem
Distributed representations are powerful but opaque. When knowledge is spread across thousands of weights, it's hard to say _what_ the network knows or _why_ it produces particular outputs. This tension between predictive power and interpretability has only grown with modern deep learning.Legacy
These criticisms sharpened connectionism rather than killing it. They led to architectures that better handle structure (recursive networks, attention mechanisms), more biologically plausible learning rules, and a more nuanced understanding of distributed representations. The old connectionist-vs-symbolic debate has given way to hybrid approaches combining both traditions.
Learn More
Further Reading
- Rumelhart, D. E., McClelland, J. L., & PDP Research Group. (1986). Parallel Distributed Processing: Explorations in the Microstructure of Cognition. MIT Press. The foundational text, freely available online.
- McClelland, J. L. (2013). Explorations in Parallel Distributed Processing: A Handbook of Models, Programs, and Exercises. An updated tutorial with interactive simulations.
- Interactive IAC Demo. Try the Jets and Sharks model yourself.