Introduction to Reinforcement Learning DRAFT
Note
This chapter authored by Todd M. Gureckis. See the license information for this book. The draft chapter means it should not be considered complete or accurate!!
Introduction
Reinforcement learning (RL) is a broad and interdisciplinary topic focused on how an agent (biological or artificial) can learn to make decisions through experience. RL is typically recognized as a distinct subfield within machine learning. However, the ideas in this field have evolved in close contact with ideas in psychological and animal learning behavior. Part of the reason is that the problem that RL aims to solve -- namely making good decisions through learning -- is a key aspect of almost all animal behavior. As a result, theories developed to explain how animals and people make decisions inevitably draw on similar concepts and ideas.
RL is an important topic within computational cognitive science because it provides a powerful set of modeling techniques for agentic behaviors (that is behaviors that involve making decisions and interacting with the environment). In addition, contemporary RL is a highly integrative field of AI that draws on related advances in probabilistic modeling, neural networks, and optimization. As a result, learning about RL can provide you with a powerful set of tools for developing models of cognition.
What is RL?
RL is often distinguished from other forms of machine learning. Supervised learning refers to a situation where a learning agent is provided with corrective feedback. For example, if a child were to look at a bird and say "dog" a helpful caregiver might correct them by saying "No, that's a bird." In this case, the child might change their behavior. Critically, the feedback provides the "correct" answer in this case. When you learned about neural networks, often we were considering cases where that were supervised learning. For example, a convolutional neural network applied to ImageNet (Deng et al., 2009) might take as input a photograph and attempt to output a label for the content of the image. Feedback to the network often takes the form of "ground truth" labels which were created by humans.

Figure 1: Some varieties of learning problems popular in machine learning. RL is distinctive in its use of evaluative feedback.
However, such corrective feedback is rarely available in our environment. Instead, we more often learn in unsupervised learning settings (Barlow, 1989). In this situation, an agent is not provided any direct feedback. Learning in this case is still possible if the learner can detect the covariational structure of the input. Perhaps the paradigmatic example of unsupervised learning is clustering algorithms. Here the goal is to group various data points that are similar without prior knowledge of the groups or explicit labels/feedback. Most contemporary large language models (LLMs) are also considered "unsupervised" because they are trained by predicting the next word of a sentence given some context of the previous words. In this case, we think of there being no "explicit" teacher but instead, the system is mining the structure of the data stream to detect structure.
In contrast to these two previous approaches, reinforcement learning refers to a situation where feedback is available but it is evaluative instead of corrective (i.e., supervised learning). Evaluative feedback is something like your grades in a class. The grade is higher when you do well and lower when you do worse but it doesn't specifically tell you what to do in any situation. You can't for instance know how to answer a question on a test given only your grade. The grade evaluates how good your behavior was. The feedback in RL (described below) is almost universally limited to a single, scalar signal called a "reward." Positive values of this signal indicate situations that are relatively good while low or negative values might be thought of as relative punishments. The goal of the agent in an RL system is to learn to act in a way that leads to earning higher rewards.
What type of learning do people use? Humans and other animals likely learn using all three methods at some level. Perhaps the broadest form of learning is unsupervised -- we watch the world unfold around us and that is sufficient in most cases to pick up patterns and structure. However, we also do receive corrective feedback from parents, teachers, and other individuals around us. Finally, we also learn from reinforcement. When we have a good meal, our brains tell us that was good (evaluative feedback), and we seek out similar experiences. Students might optimize their behavior to increase their GPA (evaluative feedback). Young children might be motivated by cookies or stickers to behave well or do their homework. Consistent with the definitions described above, the feedback in these everyday examples is evaluative because it simply sends a signal about whether past behavior is good/bad but doesn't explicitly correct the course of action or tell the agent specifically what to do.
Why reward?
You might be thinking "Why don't we just tell the agent what to do directly rather than send this relatively sparse evaluative feedback signal?" However such specific, corrective feedback is often hard to come by. In machine learning settings, this requires an "oracle" or all-knowing source of truth that can know what to do in most or all situations. If you already have such an oracle your machine learning problem is already solved! More often, we ask humans to act as "oracles" and provide correct answers for smaller sets of situations (such as in large datasets like ImageNet). But this is expensive and time-consuming and not available for many problems.
Evaluative feedback is usually easier to compute. For example, if a robot is supposed to pick up all the objects in a room and put them away, then it is easy to reward the robot based on how many of the objects were put away. Similarly, a robot could be rewarded for keeping its battery from going to zero by simply rewarding and agent with a value inversely proportional to the battery reading. Evaluative feedback tends to be easy to automate and thus this, sparser, simpler type of feedback is a more useful signal for learning.
Animal brains are equipped with specialized neural circuits for monitoring and providing rewards. For example, primary reinforcers like sex, drugs, food, and even music activate so-called "reward" systems in the brain which assign higher rewards to good over bad stimuli. This has a powerful effect on animal behavior driving adaptive behavior, and also more negative behavioral patterns such as addiction. There is therefore strong reason to believe that animal and human behavior is shaped by reward contingencies in many situations.
Of course, RL can be combined with other forms of learning including immitation (Lu et al., 2022), etc... and many of the exciting future development in RL research are about leveraging multiple types of learning.
Examples of RL applications
Applications of RL in computer science have led to increasingly remarkable applications, especially in areas related to game playing, robotics, self-driving cars, human-computer interaction, website optimization, and more.
Game Playing: Since the early days of AI, game playing has been a popular testbed for algorithms, and successes on these types of problems are among the most well-known successes of RL. For example, Gary Tesauro developed a RL agent that learned to play backgammon at a world-class level (Tesauro, 1995) using Temporal Difference Learning (more on that below). AlphaGo is a game-playing agent that leverages many techniques from the RL literature (Silver et al., 2016). The model was trained to play the game Go which had previously been considered outside the abilities of computers due to the large number of possible moves. Impressively, AlphaGo was able to beat the world champion Go play (Lee Sedol) in a series of games (which became the subjects of an interesting documentary movie).
Figure 2: A still frame from the live video feed of the AlphaGo vs. Lee Sedol match.
A related advance was a paper that developed a model that learned to play classic Atari games at a near-human level using as input the raw pixels on the screen (Mnih et al., 2015). This paper was one of the first examples of "Deep RL" - a combination of RL with deep convolutional neural networks from computer vision (more on that later).
Robotics: RL has been used to train robots to perform a wide variety of tasks. For example, RL has been used to train robots to pick and place objects, assemble items, and even fold laundry. These tasks require precise control and adaptation to varying conditions. RL enables robots to learn these tasks through trial and error, improving their ability to operate in dynamic environments. Impressive examples come daily, but one of the more famous is using RL to control autonomous drones to navigate complex environments without human intervention (Zhou et al., 2022). Similarly, RL has been used to create "robotic soccer players" who can learn to play soccer with each other (Stone, Sutton & Kuhlmann, 2005; Kitano et al., 1998).
Figure 3: A youtube video of a swarm RL controlled drones flying through a forest! Scary!
Self-Driving Cars: Companies like Waymo and Tesla use RL to develop self-driving car technology (e.g., Lu et al., 2022). In these cases, one can think of steering a vehicle as a type of dynamic control problem. RL is particularly well suited to these situations. Rewards might be given to keep the car from being in accidents, to stay in the lane, to follow the speed limit, etc... The car can then learn to optimize its behavior to maximize the reward signal.
Human-Computer Interaction: RL is used to optimize user interfaces and, increasingly, in fine-turning the behavior of large language models (LLMs) to generate more human-like text. For example, a technique known as Reinforcement Learning from Human Feedback (RLHF) has been used to train LLMs to generate more human-like text by learning from human feedback on the generated text (Ouyang et al., 2022). Similarly, one futuristic idea is that robots that might live in someone's home could be "taught" to perform different tasks by having the user of the system provide rewards to the robot for doing things correctly. In this case, the human user becomes the "teacher" and the robot the "learner" where rewards and punishments are given by the teacher to shape the behavior of the robot (Amershi et al., 2014).

These are only a few of the many applications of RL. RL is a set of techniques rather than one type of model and so the ideas can be applied to a wide range of problems.
Why is RL interesting in cognitive science?
Reinforcement learning (RL) is highly relevant to cognitive science because it provides a computational framework for understanding how humans and animals learn from their environment through trial and error. Perhaps most importantly, it takes an agentic approach in that it models a primary agent or actor interacting with a dynamic environment. This perspective is sometimes missing from the modeling frameworks we explored in the previous chapter which largely were passive and did not make decisions about how to behave and interact with their environment. For example, simple multi-layer perceptrons are fed inputs selected by the modeler and are given feedback accordingly. In contrast, an RL agent might decide to explore a certain part of their environment and reach a goal. Given that agency, control, and interaction describe the lives of animals and people, RL offers a powerful framework for understanding human cognition.
More specifically, RL algorithms can model how humans learn to make decisions based on rewards and punishments. This type of research has helped cognitive scientists understand how the mechanisms of learning and decision-making work in the brain. RL involves balancing exploration (trying new things) and exploitation (using options known to be rewarding), a topic of immense interest in cognitive science. Furthermore, RL models have been successfully used to account for how people acquire skills, habits, and other patterns of behavior. In recent years, a related field called computational psychiatry has emerged which uses models, many of which borrow from RL concepts, to study disorders like addiction, depression, and obsessive-compulsive disorder (OCD), which involve dysregulation of reward processing and decision-making (Huys, Maia & Frank, 2016). The hope is that insights from these models will inform the development of interventions and therapies that target maladaptive learning patterns.
One of the most compelling examples of RL's relevance to cognitive science is the study of dopamine's role in reward prediction error. Research has shown that dopamine neurons in the midbrain signal the difference between expected and actual rewards, closely aligning with the reward prediction error signal in RL models (Schultz, Dayan & Montague, 1997; Niv & Schoenbaum, 2008). This discovery has profound implications for understanding learning and decision-making processes, as well as for developing treatments for disorders involving dopaminergic dysfunction.
Besides the theoretical implications, RL algorithms also have useful properties when used as components within larger cognitive models. For example, many problems in cognitive science can abstractly rely on methods like dynamic programming which we discuss below (e.g., Rich & Gureckis, 2018). Similarly, the idea of learning from a reward signal can be used in many types of cognitive models including those based on very complex representations such as neural networks, and even probabilistic programs (e.g., Wang & Lake, 2019). Thus, learning about RL can provide you with a powerful set of tools for developing models of cognition.
RL integrates across Marr's Levels
As mentioned in the introductory reading, research in computational cognitive science often aims analyze behavior at different levels of analysis. In an ideal world, there would eventually be deep integration across the levels (e.g., understanding at the implementational level would align with insights from the computational level). RL is one of a few areas of cognitive science where such synergies exist. At the highest level, the problem of RL is to optimally harvest reward from a potentiall unknown environment. This computational level description highlights the rational basis for behavior and aligns well with ideas in evolution, adaption, etc... As you will read later in this chapter, algorithms developed for RL such as temporal difference (TD) learning are algorithmic solutions to a computational level challenge of optimizing reward. There are many such algorithms which, at a broad level can be seens as using computational algorithms to approximate the computational level problem. However, there is increasing evidence and belief these algorithms are also implemented in the animal brain by the dopaminergic system. Our current understanding suggests this is rare example of a computational theory that seems to connect across levels rather than proceeding independently.
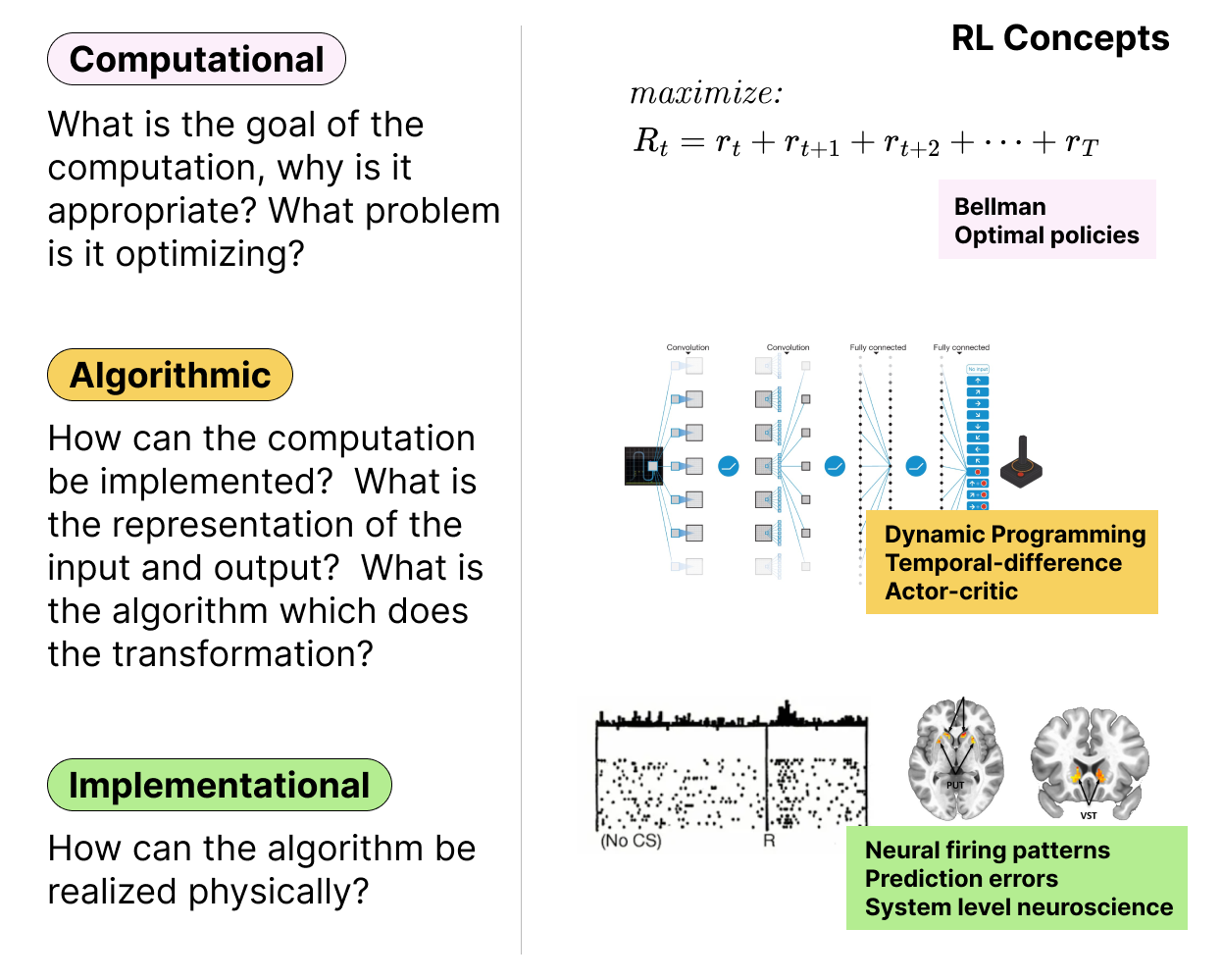
Figure 4: The left panel shows the three levels of analysis proposed by David Marr (computational, algorithmic, and implementational). The right panel shows how aspects of RL theory can be understood at each of these levels. Unlike many areas of cognitive science, research in RL tightly integrates these levels of analysis.
The Problem of RL
As we will see in this chapter, RL is not one algorithm or model but instead a constellation of ideas for how to solve certain types of learning problems. When introducing these algorithms, it helps to start with a clear definition of the problem being solved in RL.
First time with these concetps?
The following section goes through some formal definitions. If you find them confusing or abstract at first, jump ahead to the Gridworld example below and then come back to this section.
At a general level, we can think of RL as a problem involving an agent that interacts with a world or environment. The agent can take actions that change the the environment. The environment responds to the agent's actions by changing its state and providing a reward signal to the agent. The state of the world may be observed by the agent along with the resulting reward signal. The system evolves over time such that the action taken at time

Figure 5: The basic RL problem.
Let's break this down a bit more. Most RL problems can be described as a Markov Decision Process or MDP. An MDP is a mathematical framework that formalizes the problem of learning from interaction to achieve a goal. Formally, a MDP is defined by a tuple
is the set of states in the environment. is the set of actions the agent can take. is the transition function that specifies the probability of transitioning from one state to another after taking an action. is the reward function that specifies the immediate reward received after taking an action in a state. is the discount factor that determines the importance the solution should place on the future rewards compared to the present.
What do these terms actually mean though? Let's take each one in turn.
States
The state of the environment is a representation of the current situation. It is a summary of all the relevant information that the agent needs to make decisions. For example, in a game of chess, the state might include the positions of all the pieces on the board. In a robotic manipulation task, the state might include the positions of the robot's joints and the objects in the environment.
Understanding what the state is and how it changes is a key part of solving an RL problem. For humans, the state might depend on our limited perceptual abilities. For example, the true state of the environment on a busy street might be very complex but we only attend to a subset of the available information when making decisions about how to cross the street. To distinguish the state from what the agent actually perceives, we introduce the notation of an observation. The observation is the set of features of the state that the agent can actually perceive. The idea is that the environment can be considered to be in on particular state,
Actions
An action,
Transition Function
Imagine the agent is in a state
The transition function may be deterministic or stochastic. As a result, we typically write the transition function as a probability
States in a MDP have very special property which is that the future state of the environment depends only on the current state and action, not on the history of states and actions that led to the current state. This property is called the Markov property and it simplifies the learning problem and allows for efficient computation of optimal policies. Formally, a state
which is to say the probability of the next state depends only on the current state and the action taken and not on the entire history of past states. This is intuitively true for simple games like chess (the probability of the next gameboard configuration depends only on the current gameboard configuration and the move made by the current player). In addition, we typically think of everyday physical systems as following the Markov property because the position of a ball falling from a height depends on its current position and the set of forces currently present and not on the entire history of the ball's motion.
The Markov assumption might seem quite restrictive but in practice is does not strongly limit the types of problems that can be solved with RL. One reason is that the definition of a state,
Reward Function
The reward function,
The reward function provides feedback to the agent about the quality of its actions. The design of a good RL system (i.e., in computer science or engineering) involves finding good ways to design the rewards to encourage the system to do what the designer wants. For example, when designing the robotic drones mentioned above, the designers of the system want to give rewards for good things (staying in the area) while punishments for bad thing (crashing or running into obstacles).
Ultimately, the goal of the agent is to learn a way of behavior (i.e., a "policy") that maximizes the cumulative reward it receives over time. Cummulative rewards are a little different than the immediate reward
RL agents are typically tasked with learning to maximize this quantity. Evolution may have shaped animal behavior in a similar way. Maximizing long term rewards is important because sometimes better outcomes are only available after a series of more costly actions. For example, studying for an exam might locally be a bad experience, but the long term value of getting a good grade might outweight the short, immediate costs. As a result, agents can't simply optimize immediate rewards, but need to consider the long term consequences of their actions.
Discount Factor
In the MDP specification, the final terms is the discount factor,
Instead of giving equal weight to all rewards, in this case we "discount" rewards that are further into the future (
This is a desirable property because many animals (and people) are known to be a bit myopic in their decision making (Mischel, Shoda & Rodriguez, 1989; Kirby & Herrnstein, 1995; Herrnstein & Prelec, 1991) . For example, people often prefer to receive a small reward now rather than a larger reward later. The discount factor helps to encourage the agent to consider the long-term consequences of its actions and make decisions that maximize the expected cumulative reward over time.
The discount factor also is important for numerical stability. Since the sum of an infinite series of rewards can be infinite, the discount factor helps to ensure that the sum of rewards converges to a finite value. This is important for many RL algorithms that rely on the sum of rewards to estimate the value of states or actions.
One problem definition, maybe specific types
These key components help to defined a MDP and the general RL problem setting in the sense that any particular problem can be described by these components (
The factors above define the basic structure of the RL problem. However, there are a few other elements worth mentioning that often come in in solutions to MDP. The goal of the agent, faced with any particular MDP or POMDP is to learn a way of behaving that maximizes the long term reward. Often this is accomplished by solve a related problem of estimating the value of particular state or state-action pars. Let's attemp to define these these concepts as well.
Policies
A policy,
Value functions
As we being to think about how to solve RL problem it is helpful to introduce a particular concept called a value function. A value function is not strictly part of an RL problem. In fact, as we will see later, it is possible to learn good behavioral policies without ever referencing the concept of value. However, value functions are a key concept to many RL algorithms. In addition value function relate in a direct way to the concept of utility in economics and psychology.
A value function is a function that estimates the expected cumulative reward that an agent can achieve from a given state or state-action pair. There are two main types of value functions in RL: the state-value (usually denoted as
Let's focus on the first one. The value of a state,
Given this fact, we can define the value of a given state
where
The value function is a measure of how good it is to be in a particular state. The action-value function
Gridworlds
To help better understand the concepts of states, actions, rewards, and policies it can help to consider a simplified example. One common example used in RL is the gridworld problem. In this problem, an agent navigates on, typically, a 2d "world" that exists on a grid. The grid is like a maze and at any moment the agent can be in one of the grid cells. There are four actions available in each grid cell location: the agents can choose to move up, down, left, or right.
An example of a grid world is shown here:

Figure 6: Example 2D gridworld problem. The robot is in a world made of grid cells. At each moment they can only occupy one location. Actions (up, down, left, and right) move the robot between the locations. If the agent steps on the green cell they earn a large rewards (+10 points). If they step on the red cell they earn a large penalty (-10 points). The dark grey cell is a barrier and if the agent attempts to move into it they will instead remain in the same location. Each move costs the agent -1 point. Given this decription the goal of the agent is to make as much cumulative reward as possible. This is accomplished by moving efficiently to the goal location (green cell).
Notice the agent is currently at grid cell (0,0). We call this the state of the agnent. The fell set of possible states,
The agent receives a reward of -1 for each gridworld environment, moving from one cell to another, with the goal of reaching a specific target cell while avoiding obstacles or hazards.
To summarize, RL problems involve an agent interacting with an environment to learn how to make decisions that maximize cumulative, long-term rewards. The agent's goal is to develop a policy that maps states to actions in a way that maximizes the expected reward over time. The specific class of decision problems that RL addresses are called Markov Decision Processes (MDPs). There are several ways to "solve" a MDP problem and the following sections walk through three foundational approaches which help to introduce the basic ideas underlying RL.

Figure 7: An example of a good and bad solution to this particular gridworld problem. The agent starts in the lower left corner and must reach the green cell. On the right the
The Bellman Equation
Let's first return to our definition of the state-value function,
The final line above is the Bellman equation. It is one of the most important equations in RL and understanding it is essential for understanding how RL problems are solved. Let's break down what it means and why it matters.
Why is the Bellman equation important?
The key insight of the Bellman equation is that it expresses the value of a state in terms of the values of its successor states. In other words, the value of where you are right now depends on how good the places you can get to next are. This creates a self-consistency constraint on the values: the value assigned to any state must be consistent with the values of all the states it can transition to. You can't just assign arbitrary values to states -- they have to "agree" with each other according to the structure of the environment and the policy.
This self-consistency is powerful because it means that only certain assignments of values to states are valid. If the values are not self-consistent, they cannot be the true values under the given policy. This dramatically constrains the problem: rather than having to estimate each state's value independently (which would require infinitely long trajectories), we can instead find values that satisfy the Bellman equation simultaneously across all states.
Solving the Bellman equation as a system of equations
Because the Bellman equation defines the value of each state in terms of other states' values, it naturally forms a system of linear equations with
To make this concrete, consider a simple gridworld with four states
Here, each term corresponds to one of the four actions: the agent gets an immediate reward (10 or 0 depending on where it ends up) and then lands in a successor state whose value we also need to know. Writing out similar equations for states
This is just a system of four equations with four unknowns -- something you could solve with basic linear algebra! The values on the left-hand side also appear on the right-hand side, which is exactly the self-consistency property: each value is defined in terms of the others, and they all have to be solved together. In principle, for any MDP with known dynamics, we can set up and solve a system like this to find the exact values under any policy.
The Bellman equation defines the RL problem
The Bellman equation is important not just as a tool for computation but because it provides the formal foundation for what it means to solve an RL problem. In essence, the goal of RL can be understood as finding values (and ultimately policies) that satisfy the Bellman equation. Many of the algorithms we will study -- dynamic programming, Monte Carlo methods, temporal difference learning -- can be understood as different strategies for finding or approximating solutions to the Bellman equation. Dynamic programming solves it exactly (when the environment is fully known). Monte Carlo and TD methods approximate the solution through experience when the environment is unknown. In this sense, the Bellman equation is the computational-level description of the RL problem, and the various algorithms are different algorithmic-level approaches to satisfying it.
Of course, solving a system of
Overview of solution methods
Now that we have defined the RL problem and the key concepts of states, actions, rewards, policies, value functions, and the Bellman equation, the natural question is: how do we actually solve these problems? There are several foundational approaches, each with different assumptions and trade-offs:
- Dynamic Programming: Dynamic programming methods solve MDPs by computing the optimal value function or policy. These methods are based on the Bellman equations and can be used to find the optimal policy for a given MDP. Although these methods have less applicability to human cognition, they are useful for understanding the theoretical foundations of RL. In some areas, RL is known as "approximate dynamic programming" because it uses computational methods to estimate the solutions one would obtain if dynamic programming could be applied exactly. (Wong et al., 2023)
- Monte Carlo Methods: Monte Carlo methods use random sampling and simulation to estimate the value function or policy of an MDP. These methods are useful when the dynamics of the environment are unknown or when the state space is too large to be explored exhaustively. Aspects of these methods might be relevant to understanding how humans and animals plan.
- Temporal Difference Learning: Temporal difference (TD) learning methods are a class of RL algorithms that combine elements of dynamic programming and Monte Carlo methods. These methods update the value function or policy based on the difference between the predicted and actual rewards. TD learning is a powerful and flexible approach that has been used to model learning in humans and animals.
Over the next few weeks we will dive more deeply into each of these methods, exploring how they work, how they relate to one another, and how they have been used to model human and animal learning and decision-making.
Bibliography
- Deng, J., Dong, W., Socher, R., Li, L.-J., Li, K., & Fei-Fei, L. (2009). ImageNet: A large-scale hierarchical image database. 2009 IEEE Conference on Computer Vision and Pattern Recognition, 248–255.
- Barlow, H. B. (1989). Unsupervised learning. Neural Comput., 1(3), 295–311.
- Lu, Y., Fu, J., Tucker, G., Pan, X., Bronstein, E., Roelofs, R., Sapp, B., White, B., Faust, A., Whiteson, S., Anguelov, D., & Levine, S. (2022). Imitation Is Not Enough: Robustifying Imitation with Reinforcement Learning for Challenging Driving Scenarios.
- Tesauro, G. (1995). Temporal difference learning and TD-Gammon. Commun. ACM, 38(3), 58–68.
- Silver, D., Huang, A., Maddison, C. J., Guez, A., Sifre, L., van den Driessche, G., Schrittwieser, J., Antonoglou, I., Panneershelvam, V., Lanctot, M., Dieleman, S., Grewe, D., Nham, J., Kalchbrenner, N., Sutskever, I., Lillicrap, T., Leach, M., Kavukcuoglu, K., Graepel, T., & Hassabis, D. (2016). Mastering the game of Go with deep neural networks and tree search. Nature, 529(7587), 484–489.
- Mnih, V., Kavukcuoglu, K., Silver, D., Rusu, A. A., Veness, J., Bellemare, M. G., Graves, A., Riedmiller, M., Fidjeland, A. K., Ostrovski, G., Petersen, S., Beattie, C., Sadik, A., Antonoglou, I., King, H., Kumaran, D., Wierstra, D., Legg, S., & Hassabis, D. (2015). Human-level control through deep reinforcement learning. Nature, 518(7540), 529–533.
- Zhou, X., Wen, X., Wang, Z., Gao, Y., Li, H., Wang, Q., Yang, T., Lu, H., Cao, Y., Xu, C., & Gao, F. (2022). Swarm of micro flying robots in the wild. Sci Robot, 7(66), eabm5954.
- Stone, P., Sutton, R. S., & Kuhlmann, G. (2005). Reinforcement learning for robocup soccer keepaway. Adapt. Behav.
- Kitano, H., Tambe, M., Stone, P., Veloso, M., & others. (1998). The RoboCup synthetic agent challenge 97. RoboCup-97: Robot.
- Ouyang, L., Wu, J., Jiang, X., Almeida, D., Wainwright, C., Mishkin, P., Zhang, C., Agarwal, S., Slama, K., Ray, A., & Others. (2022). Training language models to follow instructions with human feedback. Adv. Neural Inf. Process. Syst., 35, 27730–27744.
- Amershi, S., Cakmak, M., Knox, W. B., & Kulesza, T. (2014). Power to the people: The role of humans in interactive machine learning. AI Magazine.
- Huys, Q. J. M., Maia, T. V., & Frank, M. J. (2016). Computational psychiatry as a bridge from neuroscience to clinical applications. Nat. Neurosci., 19(3), 404–413.
- Schultz, W., Dayan, P., & Montague, P. R. (1997). A neural substrate of prediction and reward. Science, 275(5306), 1593–1599.
- Niv, Y., & Schoenbaum, G. (2008). Dialogues on prediction errors. Trends Cogn. Sci., 12(7), 265–272.
- Rich, A. S., & Gureckis, T. M. (2018). Exploratory choice reflects the future value of information. Decisions, 5(3), 177–192.
- Wang, Z., & Lake, B. M. (2019). Modeling question asking using neural program generation.
- Kaelbling, L. P., Littman, M. L., & Cassandra, A. R. (1998). Planning and acting in partially observable stochastic domains. Artif. Intell., 101(1), 99–134.
- Mischel, W., Shoda, Y., & Rodriguez, M. I. (1989). Delay of gratification in children. Science, 244(4907), 933–938.
- Kirby, K. N., & Herrnstein, R. J. (1995). Preference Reversals Due to Myopic Discounting of Delayed Reward. Psychol. Sci., 6(2), 83–89.
- Herrnstein, R. J., & Prelec, D. (1991). Melioration: A Theory of Distributed Choice. J. Econ. Perspect., 5(3), 137–156.
- Wong, L., Grand, G., Lew, A. K., Goodman, N. D., Mansinghka, V. K., Andreas, J., & Tenenbaum, J. B. (2023). From Word Models to World Models: Translating from Natural Language to the Probabilistic Language of Thought.